Where Does Randomness Come From on a Linux Machine?
June 16, 2026
Have you ever wondered what randomness really is, and how we can get a truly random value?
I personally did, when I asked my older brother many years ago about it, and I remember insisting that a truly random value is impossible to produce; whether you come up with it (your brain handed it to you, and that was the product of underlying neural processes) or a computer hands it to you. If something caused it, how can it really be random? That's today's topic.
As that question hints, I don't believe randomness truly exists. Every action, every "bit" in this universe is backed by something that came before it. It's all just a long chain of abstractions, and for me that chain traces back to God, the starting point of everything. Otherwise we fall into an infinite regress that, at some point, stops making any sense. (Those are my personal beliefs)
So if everything is caused, how can a Linux machine hand you a value we can safely treat as random?
Part of the answer is you. On a desktop your behavior is a real source of unpredictability, the second you decide to move your mouse to where, and the exact timing of your keystrokes are things no one can predict in advance, unless they hack your mind, and Linux quietly harvests them.
But how about servers sitting in data centers that no one interacts with? And since that's where Linux is mostly used; it'd be a big deal if no real source of entropy exists! It does actually.
The kernel cares about timing, not the event
The kernel pulls that
entropy[1]from several places, and almost all of them lean on one clever trick: the kernel doesn't care about the event itself, it cares about the exact moment the event happened.
Every time something happens, the kernel reads a high resolution hardware counter (on x86 that's the TSC, the Time Stamp Counter, ticking on the order of a billion times a second), and the unpredictability lives in the lowest, jittery bits of that reading. Whether "a packet arrived" is something an attacker could anticipate, or even sit there and watch happen, is beside the point. What no realistic adversary can reproduce is that it landed at that exact instant, and not the tick before or after. That timing jitter is the entropy. Here's where it comes from.
Interrupt timing. This is the big one, and it's what keeps a headless server supplied with entropy. Every piece of hardware that needs the CPU's attention raises an interrupt: the network card when a packet lands, the disk when a read finishes, timers, USB devices, all of it. The kernel timestamps each one. Because a busy machine fires thousands of interrupts per second, the kernel mixes the timing of each one into the pool, but it credits that timing cautiously, far less than a bit of entropy per interrupt. The accounting is deliberately stingy, yet the events are frequent enough that it still adds up to a steady stream. In modern Linux it's actually the dominant source, and your keystrokes from earlier just fold into it as one more interrupt.
Disk and storage timing. When a spinning hard drive finishes a read, the precise moment depends on brutally physical things: how far the platter had to rotate, how the head settled after seeking, tiny vibrations, even minute air turbulence effects inside the sealed drive. None of that is predictable down to the nanosecond. SSDs have no moving parts, but their completion times still wobble with controller scheduling, wear leveling, and background garbage collection, so the timing stays jittery.
Network packet timing. A packet that reaches your machine has crossed switches, routers, queues, and cables, sharing every one of them with traffic from the rest of the world. Its exact arrival time is shaped by congestion you can't see, by other people's machines, by propagation delays and clock drift along the way. From inside your box, that precise arrival moment is effectively impossible to predict.
CPU execution jitter. This is the subtle and beautiful one. Run the exact same handful of instructions twice, back to back, and they will not take exactly the same number of nanoseconds. The timing wobbles because of cache hits and misses, pipeline state, memory bus contention, DRAM refresh cycles, thermal throttling, and other cores fighting over the same resources. Linux can measure this jitter directly by timing its own execution, and it leans on this mainly as a bootstrap: at early boot, before any other source has built up, the kernel will time tight loops just to get the pool initialized. A separate, dedicated design, the Jitter RNG (jitterentropy), is built to harvest this effect continuously, and that is the real lifesaver on a machine with no disk activity, no network traffic, and no human, because the chip can essentially produce entropy out of its own restlessness.
And the reason none of these can be predicted is always the same. In every case the entropy isn't really in the event, it's in the physics the event quietly exposes: mechanical vibration in a disk, thermal motion of electrons, the analog chaos inside a switching power supply, a signal propagating across the planet. These are physical processes, and even if you believe, as I do, that they're all ultimately caused, actually predicting them would demand something no attacker can ever possess: the complete microscopic state of the machine and everything touching it, down to individual electrons and air molecules, measured finer than a single clock tick. The values are caused, but the cause is buried under so many layers of physical noise that no realistic adversary can ever dig it back out.
A second kind of source: hardware built for the job
Everything up to here has been the kernel being resourceful with timing it can already measure. It never manufactured randomness; it harvested it from events that were going to happen anyway. But there is a second, completely different kind of source, and this one leans on no trick at all. It's a piece of hardware that Intel built into the CPU for exactly one purpose: to produce randomness on demand.
Here is the honest catch, stated up front. This hardware is a sealed black box welded inside the chip. You cannot open it, you cannot probe it, and you have only Intel's word for what happens inside. If it were flawed, or quietly backdoored, nothing on the outside would look any different. That is precisely why Linux refuses to trust it on its own, and we'll come back to that at the very end.
But set the suspicion aside for a moment, because the physics Intel claims here is genuinely beautiful and worth understanding on its own terms. So let's take their narrative at face value and look at how they say it works.
Intel CPUs from Ivy Bridge (2012) onward, the ones that carry the
RDRAND[2]instruction, ship with an internal Digital Random Number Generator, the DRNG, a single piece of hardware shared across every core on the processor. It works like a small assembly line, where each stage has exactly one job, and only the very first stage is truly, physically random. Everything after it is cleanup and amplification.
The entropy source: a ball on a hill
The first stage is the entropy source, and it's where the philosophy of this whole article finally gets answered in copper and silicon.
Picture a ball balanced perfectly on top of a hill, with a valley on each side. The left valley is "0", the right valley is "1". At the very top, the ball sits in what physicists call a metastable state, so finely balanced that the outcome is anyone's guess. The slightest push sends it rolling down into one valley or the other.
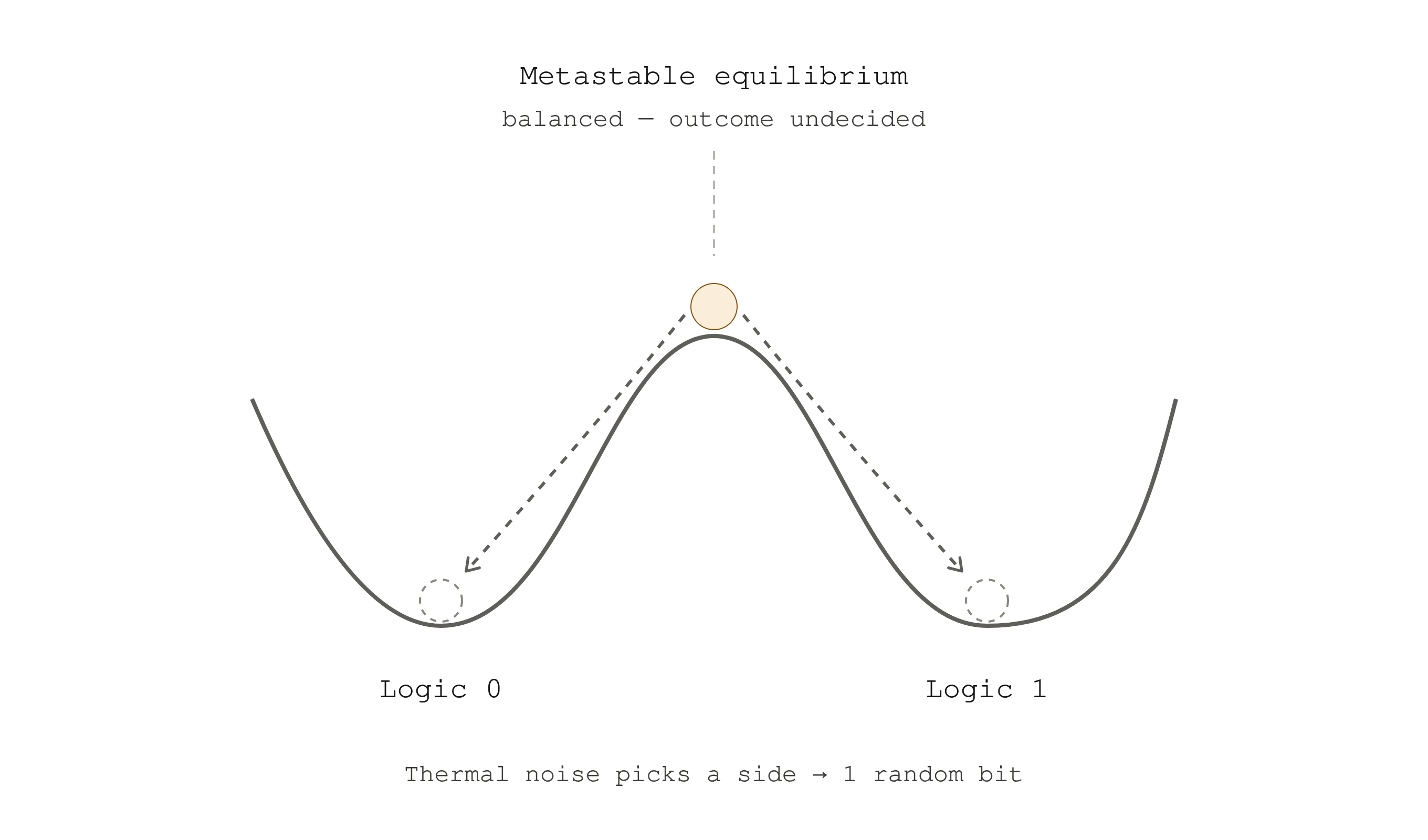
At the balance point the outcome is undecided; the tiniest nudge from thermal noise picks a side, and that's one random bit.
That's the metaphor. Here's the reality. The "ball" is a tiny circuit: two inverters wired into a loop, each one feeding the other's input. This loop has exactly two states it likes to rest in (call them Q=0 and Q=1), and those are your two valleys. Once per cycle, the hardware deliberately shoves the circuit up to the balance point with a brief reset pulse, then lets go.
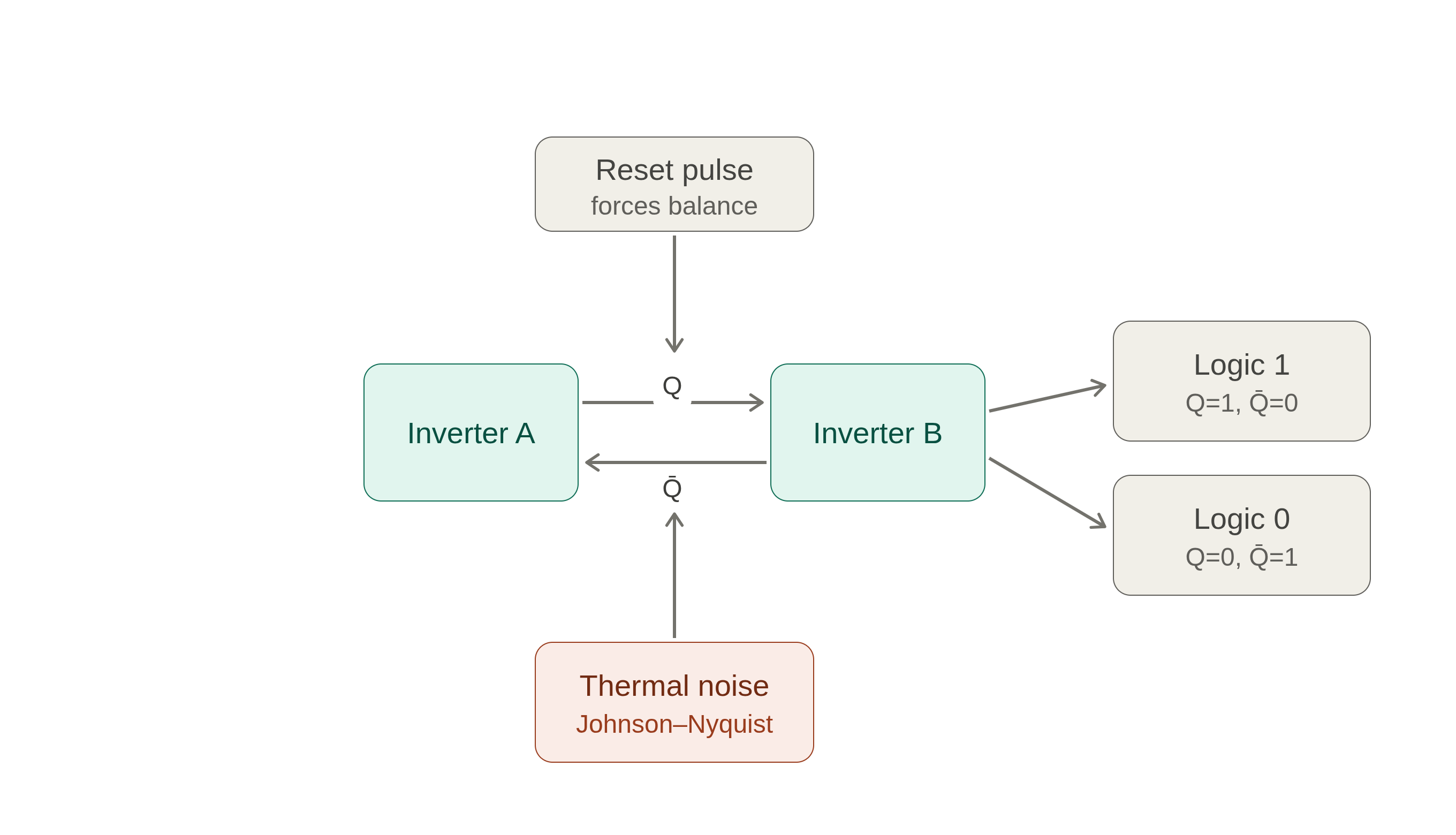
Two inverters wired into a loop form a latch with two stable states. A reset pulse drives it toward balance; thermal noise tips it to Logic 0 or Logic 1.
And what gives the ball its push? Thermal noise. In any conductor above absolute zero, electrons are in constant random motion; they jitter because they carry heat energy. This produces a faint, ceaseless, fluctuating voltage, the same hiss you hear in an analog amplifier turned all the way up, and physicists name it after Johnson and Nyquist. At the balance point every deterministic force in the circuit cancels out by design, so the only thing left to break the tie is this microscopic thermal flicker. The loop then amplifies that tiny difference exponentially fast: a few microvolts become a clean, full logic level in a fraction of a nanosecond. A thermal whisper becomes a crisp 0 or 1.
This is the closest thing we have to an answer for "where does randomness come from." To predict the outcome, you'd have to know the exact state of every relevant electron at the instant of release, and at that scale the thermal motion is something no realistic observer could ever measure finely enough to call in advance. Whether that counts as "truly random" or merely "unpredictable to any possible observer" is exactly the question I opened with. And for a computer, the difference doesn't matter.
A settled bit is sampled off the circuit, and the whole cycle repeats, billions of times per second.
Cleaning up the raw bits
But the raw bits coming straight off this circuit are not perfect, and it pays to be exact about what that means, because the obvious reading of it is wrong. It does not mean the bits arrive in some balanced arrangement that occasionally slips out of line. A genuinely random source is under no obligation to hand you equal numbers of 0s and 1s in any given stretch; it is supposed to produce long runs and lopsided patches from time to time, and a stream with no streaks in it would be the suspicious thing. Randomness lives in the probability behind each bit, not in how the tally happens to fall in any one sample, and you cannot judge a source by counting symbols in a handful of its output.
What is actually imperfect is that probability, and the independence between one bit and the next. The source is slightly biased: its chance of producing a 1 is not exactly one half, so one symbol turns up more often than the other. And its bits are slightly correlated: the last bit it produced shifts the odds on the next one by a hair, a direct consequence of the feedback that keeps nudging the circuit back toward its balance point. Neither is something you would notice by glancing at the stream, but the two are very different in size. A bias of a few percent gives itself away almost at once to a simple count of ones against zeros; what genuinely needs a large sample is the faint correlation, the slight echo of one bit in the next. And the bias is not even fixed: it drifts as the chip's temperature and voltage move around.
When Intel's own entropy source was measured, this is exactly the shape the imperfection took. Bias was the dominant problem, running around 12 percent on a typical part and climbing to nearly 25 percent on the worst one tested. The correlation between adjacent bits was far smaller, no more than a few percent, with a faint periodic "ringing" layered on top: tiny correlations near one percent, where a short pattern of two or three bits, once it appears, becomes very slightly more likely to appear again. These are small numbers. But in cryptography any predictable lean, however slight, is an edge an attacker can pry on, so none of it can be left in.
That leftover structure, the residual bias and correlation, is precisely what the three stages behind the entropy source exist to scrub out.
The first stage behind the entropy source is a set of health tests, and it is worth being clear about what they guard against, because it is not quite what it looks like. They do not measure how random the output is. They are a failure detector for the physical source: dedicated logic watches every 256 bit block as it comes off the circuit, counts how often a handful of short patterns appear, and checks each count against a fixed range. A block passes only if all of them land inside their bounds. Those bounds are Intel's own, set empirically rather than derived from first principles, and they are listed below.

A 256 bit sample counts as healthy only if every one of these six patterns occurs within its range. These are broad failure checks, not a fine gauge of entropy: even ideal randomness trips them once in a while.
What they catch is a source that has broken in an obvious way: stuck at all zeros, stuck at all ones, locked into a simple 0101... oscillation, or badly skewed toward one symbol. They are alarms, not filters. Tuned this broadly, they wave honest randomness through, streaks, long runs and all, the large majority of the time, and they trip on roughly one ideal sample in a hundred purely by chance. So a single failed sample means nothing on its own; the source is only judged unhealthy when fewer than half of its last 256 samples pass, and only a genuinely degenerate source stays below that line.
This is where the brute force worry, and the modest security payoff, both live. In healthy operation these checks add no randomness and change nothing for an attacker; the entropy does that work on its own. What they remove is an entire failure mode, whether it arrives by accident or because someone is deliberately glitching the chip to force it into one of those states. If the circuit broke and began emitting, say, all zeros, and that output were trusted as good entropy, every key and nonce drawn from it would come from a tiny, predictable set. The effective keyspace would collapse from astronomically large down to a handful of values, and an attacker would need nothing clever at all; they could simply try the few that remain. Closing off those degenerate states is only a small reduction in attack surface, but a vital one: it is the difference between a source that fails safely and one that quietly hands out guessable secrets. A sufficiently sick source makes the whole unit fail closed, stopping altogether rather than handing out weak numbers.
Second, the conditioner. This stage cryptographically squeezes the raw, slightly biased bits into compact, high quality entropy. It uses AES, in a construction called CBC MAC, to distill a block of imperfect raw bits down into a smaller block of near perfect ones. Whatever bias survived the source gets washed out here.
Third, the generator (the
DRBG[3]).
That clean entropy seeds a cryptographic generator built into the hardware. Give it one good seed and it produces a fast, effectively unlimited stream of random looking values, while quietly pulling fresh entropy from the source to reseed itself, so its output never drifts toward being predictable.
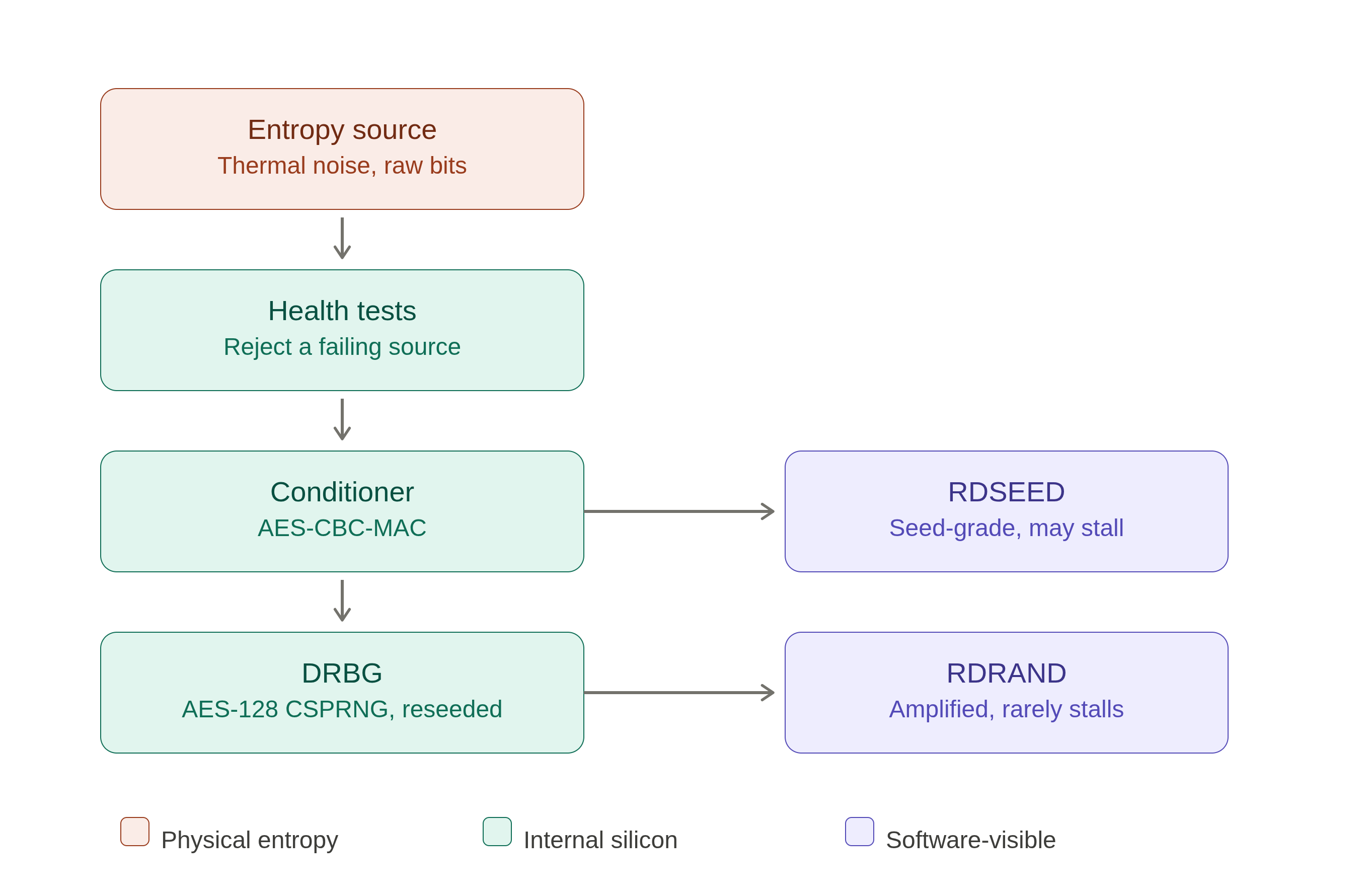
The full pipeline: physical entropy is harvested, checked, conditioned, then amplified. RDSEED taps the conditioned entropy directly; RDRAND taps the generator's output.
RDSEED and RDRAND: a well and a pump
That whole machine is exposed to your code through two instructions, RDRAND (which arrived with Ivy Bridge) and RDSEED (added two generations later, with Broadwell). The difference between them is the difference between a well and a pump:
-
RDSEEDhands you the conditioned entropy straight from the source, the output of that distillation stage. It's slower, because it's limited by how fast the physical noise can actually be harvested, so it can occasionally make you wait. But it's seed grade: the closest thing to the physical "truth," meant for seeding your own generator. -
RDRANDhands you the output of the built in generator: fast, practically unlimited, and what you'll reach for almost every time. It's technically pseudorandom, but it's seeded by real physical entropy and reseeded constantly, so for every practical purpose it's as good as random.
And both can fail, which matters more than it first sounds. Neither instruction is guaranteed to succeed on any given call; each one reports whether it actually handed you fresh randomness by setting the processor's carry flag. If the flag comes back clear, the value you got is meaningless and you're expected to retry. RDRAND almost never refuses, because the generator behind it is fast and practically bottomless. RDSEED refuses far more often, because it's rate limited by how quickly the physical source can produce real entropy: lean on it hard enough and the well runs dry until the source catches up. That's the well versus pump distinction again, now showing up directly in the failure behavior.
A simple rule of thumb, if you are working at the instruction level: use RDSEED
to seed something and walk away; use RDRAND when you just need a stream of good
random numbers, right now. Ordinary application code should usually stay one
level higher and ask the operating system, through getrandom() or equivalent,
instead of talking to the CPU instruction directly.
And that's the hardware: a sliver of genuine physical unpredictability, cleaned up and amplified into a firehose of usable random bits.
Why Linux never leans on one source alone
So now we've seen the main sources we've walked through: your own typing and mouse movements, the timing of interrupts and disk reads and network packets, the chip's own execution jitter, and finally this dedicated thermal noise source behind RDRAND and RDSEED. And yes, Linux happily uses this hardware source too, pulling from RDRAND and folding its bits in with all the rest.
But here's the part I find genuinely clever, and it's the perfect note to end on. Linux never lets this hardware source stand on its own. It will trust the CPU's generator to a point, on many distributions a switch called random.trust_cpu is on by default, letting RDRAND seed the pool at boot, but it never hands you those bits raw; they always go through the pool first. The reasoning is the one that should make you wary of any sealed black box: the DRNG is welded inside the CPU, something you can never pry open and audit from the outside, so if it were ever flawed, or quietly backdoored, you would have no way to know. And the same caution applies to every other source on its own: a sensor can fail, a timer can turn out too regular, an input can be guessed.
So rather than rest the whole system on one "best" source, Linux mixes them. It pours all of them, your input, the interrupt and disk and network timing, the CPU's restlessness, and the hardware RNG, into a single shared pool, and stirs the whole thing together with cryptography. The beauty of mixing is this: as long as just one of those ingredients carries real unpredictability, the final result is safe, even if every other source turned out to be broken, biased, or backdoored. No single source has to be the one thing standing between you and a predictable key. It's a robust way to build randomness, and it's why you can rely on a Linux machine to hand you a value you can safely treat as random, without staking everything on any one piece of hardware being honest.
So how does the
kernel RNG implementation[4]actually gather all of this, mix it, and serve it out? That pool is worth opening up, because the machinery behind it changed in an important way.
Before Linux 5.17 and 5.18, there was a way of mixing these bits, and after that the legendary Jason Donenfeld gutted and rewrote it in Linux 5.17 and 5.18 in a more secure way. The old design was not handing out weak random values or anything like that, but it had some weaknesses that we'll talk about, and Jason improved them, and we'll talk about the new design too.
Its output path already used
ChaCha20[5], and there was no practical attack making
/dev/urandom or getrandom()[6]
predictable. The weaknesses were architectural and cryptographic: the input mixer was linear and reversible, and extraction leaned on a specialized
SHA-1[7]construction. It's worth seeing the old shape first, because it explains exactly what the new one is built to fix.
The old input pool
The old system had one main input pool of 4096 bits:
128 words x 32 bits = 4096 bitsEntropy sources eventually contributed data into this pool, and two operations
acted around it. _mix_pool_bytes() incorporated new data, and the extraction
routine hashed the pool with SHA-1 to produce the secret material that refreshed
the ChaCha20 CRNG. The high-level path was:
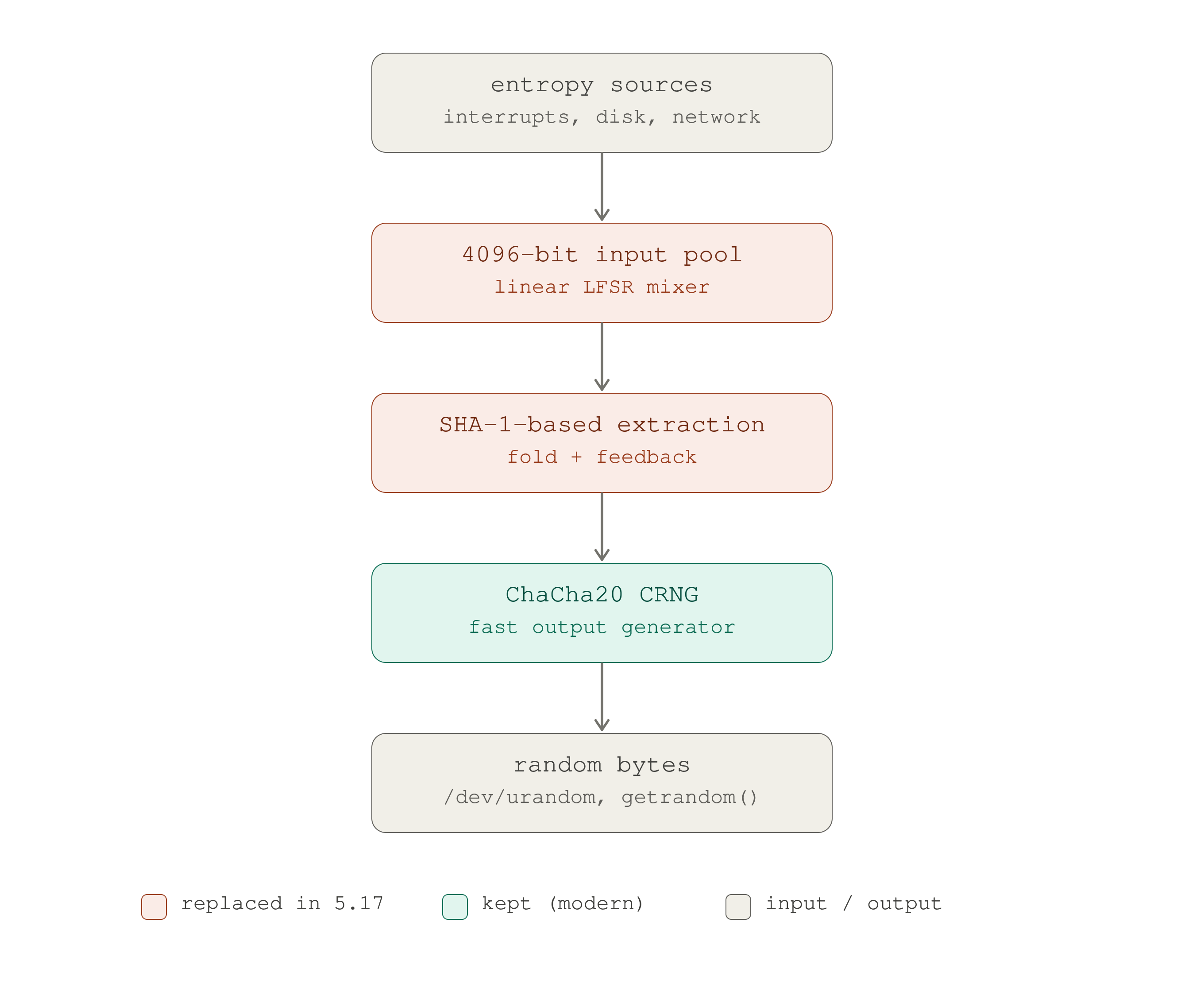
The old path. The 4096-bit linear pool and the SHA-1 extractor (in red) are the parts rewritten in 5.17. ChaCha20 at the output (green) was already modern and stayed.
ChaCha20 was already the modern output primitive. The structural weaknesses lived in the input-pool mixer and the SHA-1 extraction construction.
The old mixer was linear, and reversible
The old _mix_pool_bytes() used a twisted generalized feedback shift register
over the 128-word pool. Its taps corresponded to the primitive polynomial:
x^128 + x^104 + x^76 + x^51 + x^25 + x + 1which is just a compact description of which pool words got combined on each update. For every incoming byte, the routine rotated the input, XORed it with the current pool word and several tapped words, and applied a twist:
(w >> 3) ^ twist_table[w & 7]The rotation, the tapped combinations, the XORs, and the twist were all linear over GF(2). "Linear" here does not mean the mixer failed to spread changes; it diffused reasonably fast, and a changed input bit could touch several pool words. The real problem is that the diffusion was only linear. It built no one-way barrier.
A linear function is not automatically invertible, but this particular transformation was reversible when the resulting state and the mixed input were known. The consequences matter. If an attacker knew the resulting pool state and the inputs that had been mixed in, they could algebraically reconstruct an earlier state. Known inputs could be peeled back out by reversing the same linear relations. And with the full state plus enough control over future inputs, an attacker could in principle compute inputs that steered or cancelled parts of the state.
This was never a practical attack on ordinary Linux output. The pool state was meant to stay secret, and extracted values still passed through SHA-1 before the CRNG used them. But the weakness was structural: the security boundary between the accumulated pool and the extracted secret rested almost entirely on that single SHA-1 step at the exit. A stronger accumulator should stay hard to manipulate even after an attacker learns something about its internal state, and the old mixer gave you no such guarantee.
Leaning too hard on SHA-1
It pays to separate two different attacks on a hash function. A collision attack finds two inputs with the same digest; a preimage attack starts from a digest and tries to recover an input that produces it. The practical breaks against SHA-1, SHAttered among them, were collision attacks. They did not break preimage resistance, and the entropy extractor did not lean primarily on collision resistance. So it is simply wrong to say "SHA-1 collisions were found, therefore the Linux RNG was broken." There was no evidence the SHA-1 extractor ever returned predictable bytes.
The construction was still outdated and awkward, though. SHA-1 produces 160 bits, but the code did not return all of them. It mixed the full digest back into the pool, folded the digest words, and exposed only 80 bits per extraction:

The SHA-1 digest was used two ways at once: the full digest fed back into the pool, while only a folded 80-bit slice was actually exposed.
The feedback gave backtracking protection, helping stop a later state compromise from revealing earlier extracted values unless the hash could be reversed. The folding and truncation kept more hash material secret than was handed out. Each operation had a reason, but together they made a specialized construction that was harder to analyze and maintain than a direct modern keyed design, and it provided only about 80 bits of forward-security strength. SHA-1 needed replacing not because of its reputation, but because the construction exposed only 80 bits, depended on feedback and folding to fake properties a keyed primitive gives you directly, used SHA-1 in a way that taxed reviewers, and was built on a primitive already retired everywhere else. A newer primitive could offer better performance, a larger margin, and a native keyed mode.
The new design
The new design is two connected paths. One collects and accumulates entropy
(interrupt events and other sources flowing into the pool); the other turns that
accumulated entropy into output (the pool feeding base_crng, then the per-CPU
generators). Put together, the simplified path is a single spine:
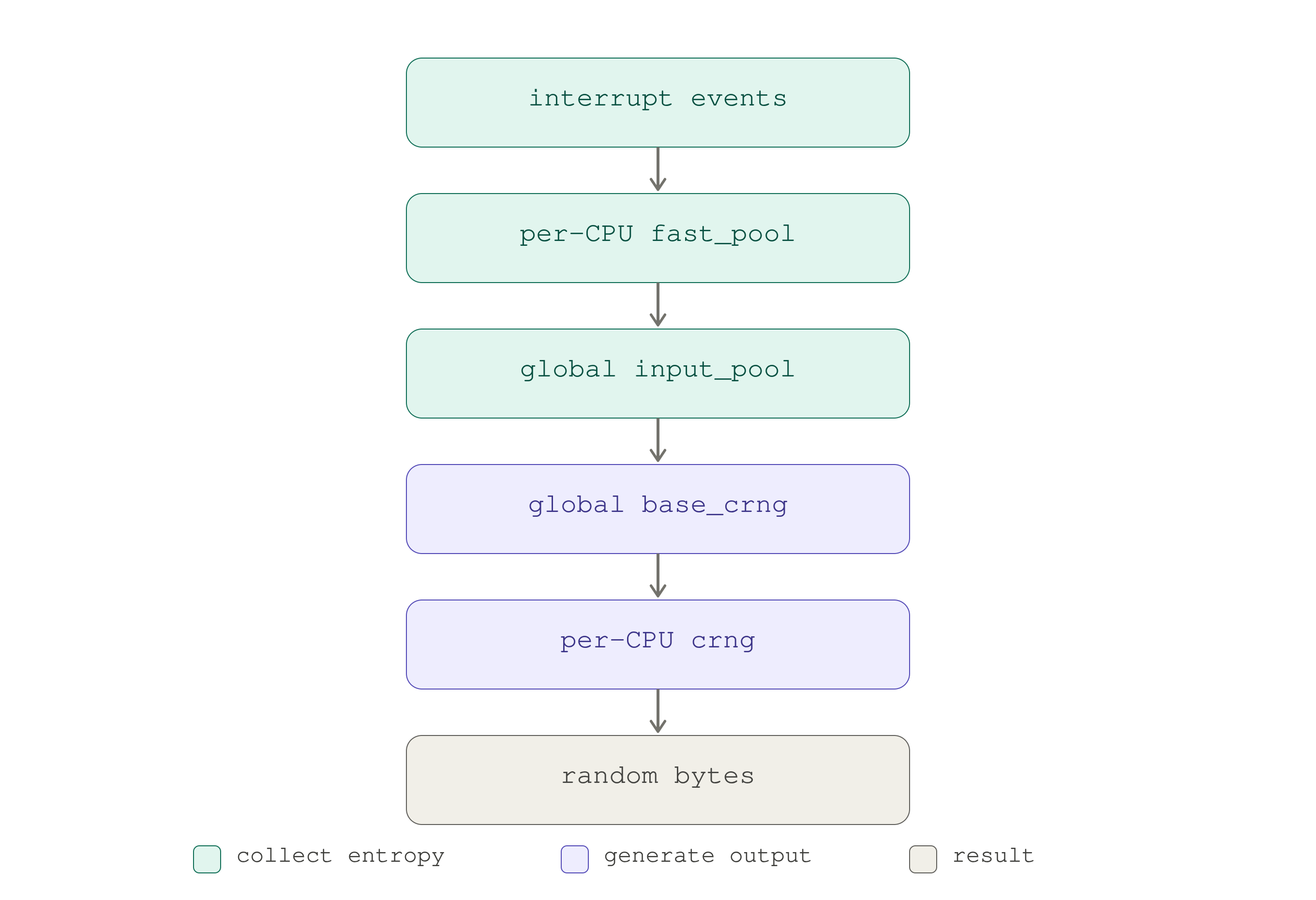
The two phases on one spine: the green stages collect and accumulate entropy
into the input_pool; the purple stages turn it into output, ending in the
random bytes you actually receive.
The per-CPU fast_pool belongs to the input side; the per-CPU struct crng
belongs to the output side.
Where entropy is merged
The central accumulator is the global input_pool:
static struct {
struct blake2s_ctx hash;
spinlock_t lock;
unsigned int init_bits;
} input_pool;The old 4096-bit array is gone as the main accumulator. The new pool is a
BLAKE2S[8]hash context, and new data is absorbed through it:
static void _mix_pool_bytes(const void *buf, size_t len)
{
blake2s_update(&input_pool.hash, buf, len);
}
static void mix_pool_bytes(const void *buf, size_t len)
{
unsigned long flags;
spin_lock_irqsave(&input_pool.lock, flags); // lock
_mix_pool_bytes(buf, len); // mix new entropy
spin_unlock_irqrestore(&input_pool.lock, flags); // then unlock
}This is the common destination for entropy and diversification data, most of it mixed straight in. Interrupt timing takes a different path, because interrupt handling is brutally performance-sensitive, and here's why:
Why each CPU gets its own fast_pool
Linux keeps one fast_pool per logical CPU:
static DEFINE_PER_CPU(struct fast_pool, irq_randomness);A logical CPU is a Linux CPU ID; on a chip with simultaneous multithreading the two hardware threads of one core normally appear as two logical CPUs, each with its own storage. There are two reasons for this.
The first is lock contention. The global input_pool has one spinlock. If every
interrupt on every CPU called mix_pool_bytes() directly, all CPUs would fight
over it:
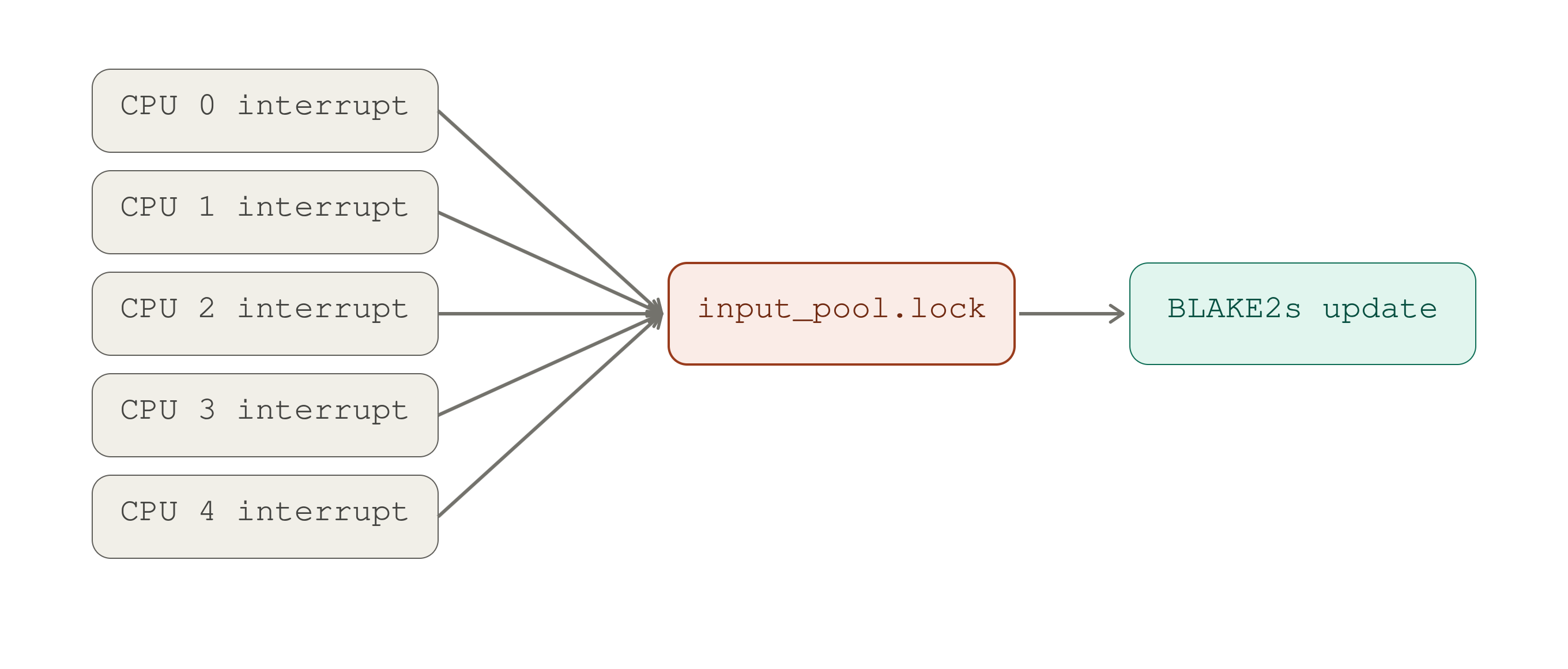
With one global lock, every CPU's interrupt funnels through
input_pool.lock before the BLAKE2S update, so they all contend for the
same cache line.
and the cache line holding the lock and hash state would bounce between CPUs. Per-CPU pools sidestep that:
![Four CPUs, each with an arrow to its own fast_pool: CPU 0 to fast_pool[0], CPU 1 to fast_pool[1], and so on. No shared destination.](/images/randomness/per_cpu_fast_pools.png)
Each CPU mixes its interrupts into its own fast_pool, so there is no
shared lock to fight over on the hot path.
The fast pool has no shared global lock, and it doesn't need one. Each logical CPU has its own fast pool instance, so two CPUs never touch the same one. A lock exists to stop concurrent accessors from corrupting shared state, but here nothing is shared across CPUs to protect: CPU 0 writes only to CPU 0's pool, CPU 1 only to CPU 1's. The cross-CPU concurrency a lock would guard against never arises, so there's no lock to take and release.
What's left is coordination on a single CPU, between the frequent interrupt updates and the occasional flush that drains the pool (yes this is a concurrency problem even on one core), and that needs no lock either. The flush worker briefly disables local interrupt while it copies and zeroes the pool, so an interrupt can't land mid-copy. That's what would otherwise let the two step on each other, and holding interrupts off for that copy closes it. Compare a single global pool: every CPU writes to it, so every update takes and releases the lock, and the cache line holding both the lock and the pool's hash state bounces between cores on every interrupt.
The second reason is keeping BLAKE2S off the interrupt path. BLAKE2S is a real cryptographic hash, several rounds of nonlinear work per block, and interrupt handlers have to finish fast. Hashing on every interrupt, and taking the global lock to do it, would pile heavy work onto one of the hottest paths in the kernel. The fix is batching:

Many cheap per-CPU updates collapse into one occasional locked BLAKE2S update.
The cheap interrupt mixer
The interrupt does only a cheap local mix, based on a reduced HalfSipHash-style permutation:
static void fast_mix(unsigned long s[4], unsigned long v1, unsigned long v2)
{
s[3] ^= v1;
FASTMIX_PERM(s[0], s[1], s[2], s[3]);
s[0] ^= v1;
s[3] ^= v2;
FASTMIX_PERM(s[0], s[1], s[2], s[3]);
s[0] ^= v2;
}This is deliberately cheap. It is not a standalone cryptographic pool and provides no security on its own. Its only job is to quickly disperse interrupt data into a temporary per-CPU state until the global BLAKE2S accumulator can absorb it.
What gets mixed comes from the collector:
unsigned long entropy = random_get_entropy();
struct fast_pool *fast_pool = this_cpu_ptr(&irq_randomness);
struct pt_regs *regs = get_irq_regs();
fast_mix(fast_pool->pool, entropy,
(regs ? instruction_pointer(regs) : _RET_IP_) ^ swab(irq));So the two values folded in are a cycle-counter or timing value, and the interrupted instruction pointer (or the current return address when registers are unavailable) combined with the interrupt number. Then the event count ticks up:
new_count = ++fast_pool->count;Deferring the real mix
After the cheap local mix, the interrupt does not hash into input_pool
immediately. It checks whether a deferred mix is already in flight, then whether
enough has accumulated:
if (new_count & MIX_INFLIGHT)
return;
if (new_count < 1024 && !time_is_before_jiffies(fast_pool->last + HZ))
return;When the count crosses the threshold or about a second elapses, it marks the work in flight and schedules the per-CPU timer:
fast_pool->count |= MIX_INFLIGHT;
if (!timer_pending(&fast_pool->mix)) {
fast_pool->mix.expires = jiffies;
add_timer_on(&fast_pool->mix, raw_smp_processor_id());
}One subtlety: count is not always the raw number of interrupts. Other
hard-interrupt timing collectors can bump it by larger amounts based on their
entropy estimate, so "1024 count units" is more accurate than "exactly 1024
interrupts."
The timer eventually runs mix_interrupt_randomness() in timer softirq context.
It confirms it is on the right CPU, disables local interrupts, and snapshots the
per-CPU state. The fast pool holds four words, but only two are copied out; the
other half stays as carried state for future events. It also captures and resets
the count:
unsigned long pool[2];
memcpy(pool, fast_pool->pool, sizeof(pool));
count = fast_pool->count;
fast_pool->count = 0;
fast_pool->last = jiffies;Then, after re-enabling local interrupts, the copied words go into the global pool, which is the point where the lock is taken and BLAKE2S runs:
mix_pool_bytes(pool, sizeof(pool));It credits initialization bits, then wipes the stack copy:
credit_init_bits(
clamp_t(unsigned int,
(count & U16_MAX) / 64,
1,
sizeof(pool) * 8));
memzero_explicit(pool, sizeof(pool));Mixing is not the same as crediting
Linux keeps two ideas apart: mixing data into the pool, and crediting it as some
number of entropy bits. mix_pool_bytes() changes the BLAKE2S state;
credit_init_bits() updates the entropy estimate. Not everything mixed in is
credited. A device serial number or a VM identifier can help make machines differ
from each other without being secret or unpredictable, so it can be mixed without
raising the credited count. This is what stops Linux from claiming more entropy
than it can justify.
How BLAKE2S replaces the linear pool
The old design stored a big explicit array and updated it with a reversible linear
transform. The new one stores a BLAKE2S context and absorbs through
blake2s_update(). The win is not better diffusion, since the old mixer already
spread changes. The win is cryptographic one-wayness. Computing inputs that cancel
or steer a known state is now meant to be infeasible, and reconstructing earlier
accumulator states from a later one is no longer a linear-algebra exercise. The
accumulation stage itself now carries weight in the security argument.
Extraction
Eventually the kernel has to turn the accumulated BLAKE2S state into a fixed-size
secret to seed or refresh the generator. Extraction does not mean copying bytes
out of a buffer; it means cryptographically deriving a compact secret from the
whole state. extract_entropy() first gathers any architecture-provided random
values (falling back to timing), then, holding the lock, finalizes the
accumulator:
blake2s_final(&input_pool.hash, seed);From that 32-byte seed, the pool's secret, the kernel derives a separate
next_key and immediately reinitializes the pool in keyed mode:
block.counter = 0;
blake2s(seed, sizeof(seed),
(const u8 *)&block, sizeof(block),
next_key, sizeof(next_key));
blake2s_init_key(&input_pool.hash,
BLAKE2S_HASH_SIZE,
next_key, sizeof(next_key));The output material is derived separately, by bumping the counter and applying keyed BLAKE2S again:
++block.counter;
blake2s(seed, sizeof(seed),
(const u8 *)&block, sizeof(block),
buf, output_length);So the next pool round starts from a fresh secret key while the output comes from a different counter, keeping the next-pool key separate from the bytes handed to the CRNG.
The global base_crng
The root generator state is:
static struct {
u8 key[CHACHA_KEY_SIZE];
unsigned long generation;
spinlock_t lock;
} base_crng;Its job is to hold the current global root key from which fresh per-CPU keys are
derived. When the kernel refreshes it, crng_reseed() asks extract_entropy()
for a new 32-byte key, installs it, and bumps the generation:
u8 key[CHACHA_KEY_SIZE];
extract_entropy(key, sizeof(key));
memcpy(base_crng.key, key, sizeof(base_crng.key));
base_crng.generation++;To seed a generator is to give it secret starting material; to reseed it is to refresh that material later from newly accumulated entropy.
Per-CPU output generators
Linux also defines one output CRNG per logical CPU:
struct crng {
u8 key[CHACHA_KEY_SIZE];
unsigned long generation;
local_lock_t lock;
};
static DEFINE_PER_CPU(struct crng, crngs);This solves a different contention problem from the fast pool. The fast pool keeps
interrupt collectors off the input-pool lock; the per-CPU CRNG mirrors that on the
output side, keeping random-byte consumers off one global ChaCha20 state. Each CPU
draws from its own crng[N], so most requests generate output from local state
without touching a shared cache line. The local_lock_t is still needed, because the same CPU runs different
kernel contexts, including preemptible and interrupt-related code, and two local
contexts must not rewrite the same key at once.
Key distribution is lazy. The base_crng does not push a key to every CPU on each
refresh. When code requests bytes, Linux picks the current CPU's CRNG and compares
generation numbers:
crng = raw_cpu_ptr(&crngs);
if (crng->generation != base_crng.generation)
/* local key is stale: derive a fresh one */If they match, the local key already descends from the current root key. If they
differ, the CPU derives a new local key. It's a pull model: base_crng is
refreshed, the per-CPU keys stay put, and each CPU only catches up the next time
it asks for bytes and notices the mismatch.
The derivation does not copy base_crng.key around. It calls:
crng_fast_key_erasure(base_crng.key,
chacha_state,
crng->key,
sizeof(crng->key));which runs one 64-byte ChaCha20 block and splits it: the first 32 bytes replace the base key, the second 32 become this CPU's key.
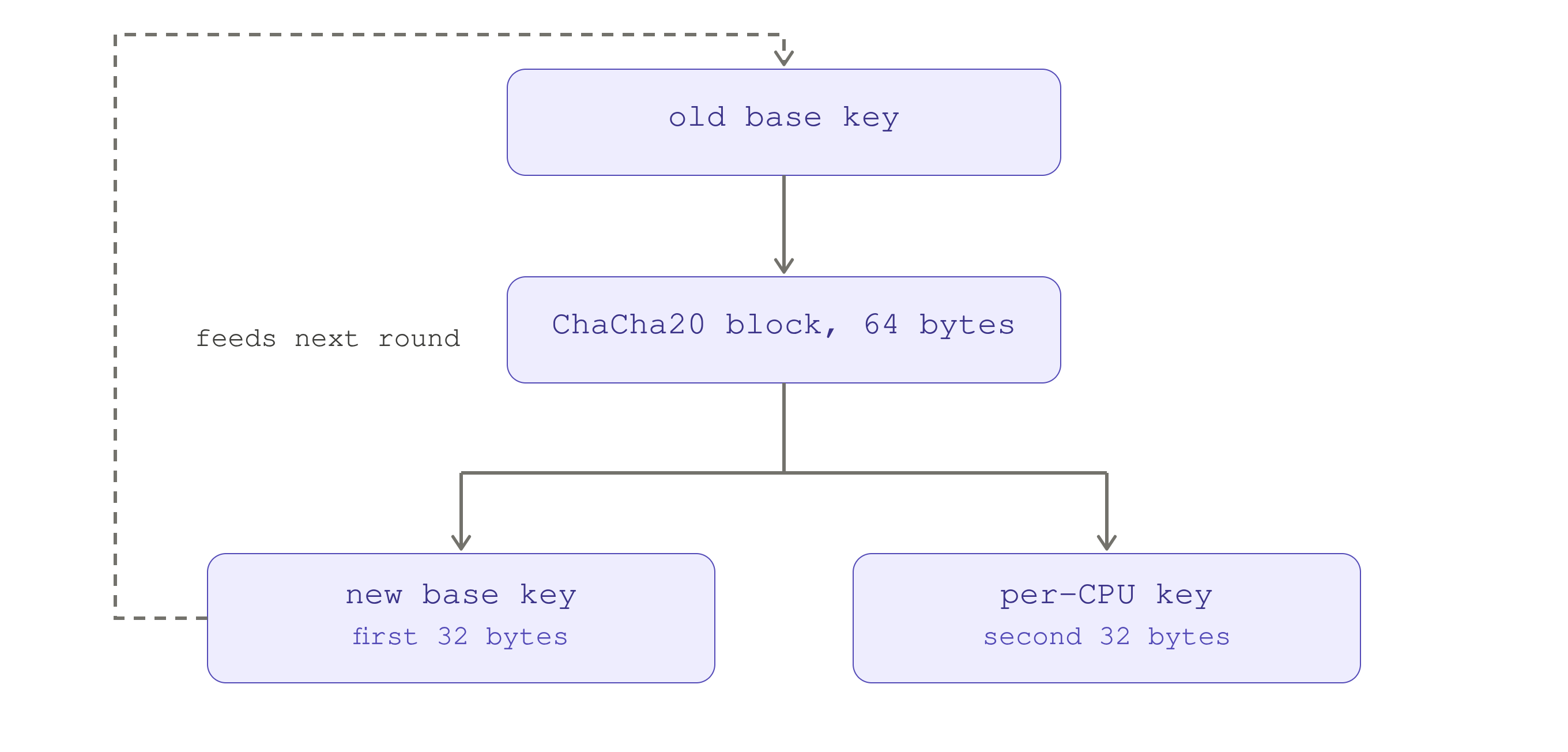
The same fast-key-erasure trick at the root: one ChaCha20 block splits into a
new base_crng key (rolled forward for next time) and the per-CPU key handed
to this CPU, so no two CPUs ever get the same key.
Because the base key changes after each derivation, no two CPUs get identical
keys. Afterward the CPU records crng->generation = base_crng.generation.
What generation means
generation is a version number, nothing more. It is not an entropy counter, a
ChaCha20 block counter, a byte count, the CPU number, or an interrupt count. It
answers one question: was this per-CPU key derived from the current base_crng
key version? For example:
base_crng.generation = 12
crng[0].generation = 12 current
crng[1].generation = 11 stale
crng[2].generation = 12 current
crng[3].generation = 9 staleWhen CPU 1 asks for bytes it sees 11 != 12, derives a fresh key, and sets its
generation to 12. CPU 2 sees 12 == 12 and generates without touching
base_crng. The number changes when base_crng is reseeded from new pool
material, not every time a CPU emits bytes.
Fast key erasure
When bytes are actually requested, Linux calls crng_fast_key_erasure() with the
current CPU's key. It builds a temporary ChaCha20 state, zeroes the counter and
nonce, and generates the first 64-byte block. The first 32 bytes replace
crng->key; the second 32 bytes are the random output. So each request rolls the
key forward:
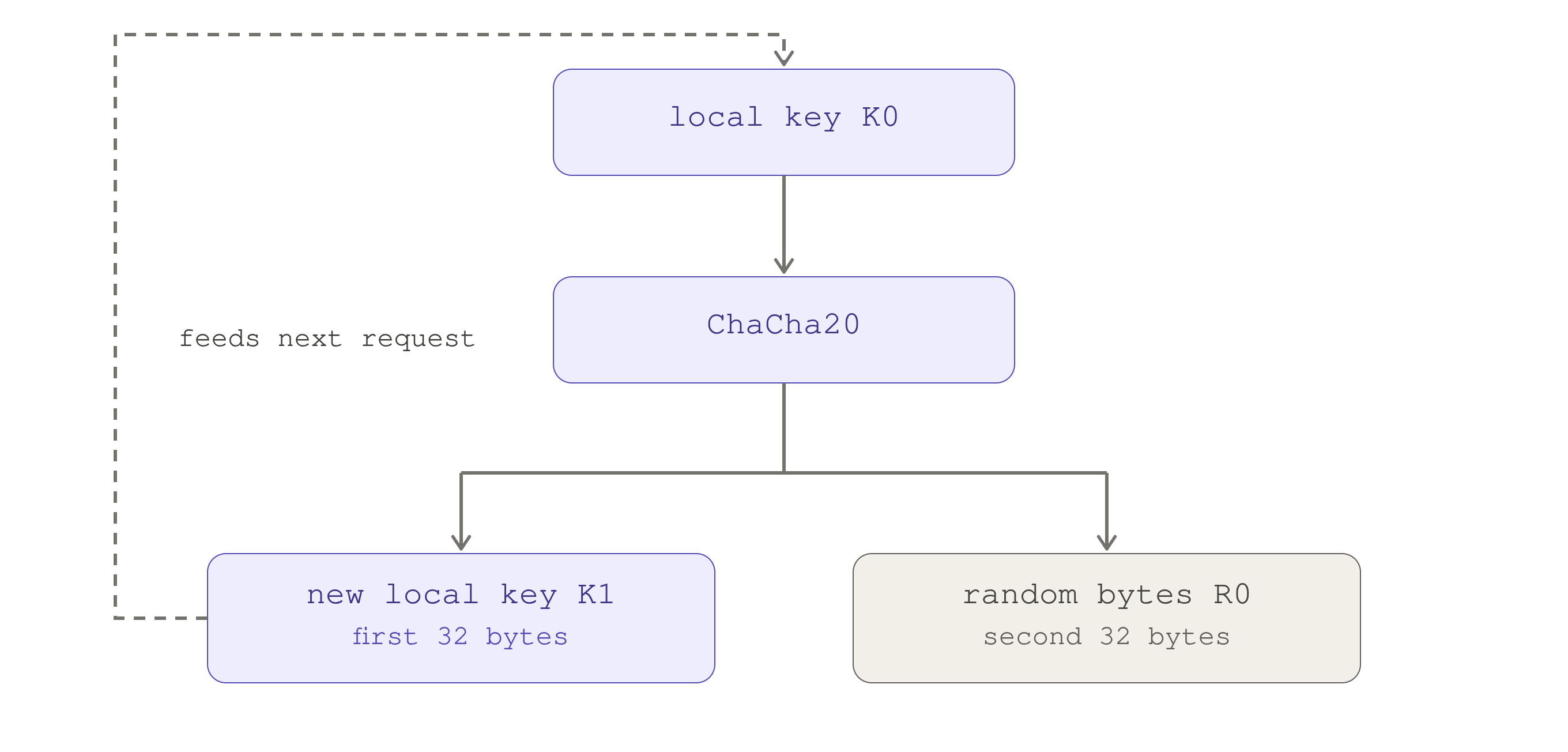
Each request runs the current key through ChaCha20 and splits the output:
the first half becomes the next key K1 (feeding the following request),
the second half is the random output R0. K0 is then gone.
The old key K0 is overwritten, the current key becomes K1, the caller gets
R0, and the next request does K1 -> ChaCha20 -> K2 + R1. That is fast key
erasure: the key that produced your bytes no longer exists, so a later compromise
of the state cannot walk backward to reproduce them. If a caller wants more than
32 bytes, the function keeps generating 64-byte blocks from the temporary state
until the buffer is full, then erases it.
The whole picture
Putting the structures together, the input side stages interrupts per CPU and flushes them into the global pool, other sources mix straight in, and the output side extracts a secret and fans it out lazily to per-CPU generators.
On the input side, the batched interrupt path and the occasional direct sources both empty into the one global pool:
![Accumulation into the pool. The batched interrupt path runs interrupt on CPU N to fast_pool[N] to a periodic deferred flush, which feeds the global input_pool. Separately, occasional direct sources (hardware RNG, bootloader seed, device data, VM identifiers, suspend timing, other timing data) mix straight into the same global input_pool.](/images/randomness/modern_rng_accumulation_into_pool.png)
Interrupts are staged per CPU and flushed in batches; direct sources, a
hardware RNG, a bootloader seed, device data, VM identifiers, suspend
timing, mix in straight. Everything lands in the single BLAKE2S
input_pool.
On the output side, that pool is extracted once and the secret flows down a single spine to the per-CPU generator that actually hands you bytes:
![The generation spine. The global input_pool is extracted into a 32-byte secret, which seeds the global base_crng, which drives lazy per-CPU key derivation, producing crng[current CPU], which runs ChaCha20 with fast key erasure to emit random bytes.](/images/randomness/modern_rng_generation_spine.png)
Extraction pulls a 32-byte secret from the pool into base_crng; each CPU
lazily derives its own crng key and runs ChaCha20 with fast key erasure to
produce the bytes.
Each object has one job. fast_pool[N] is a cheap per-CPU staging area for
hard-interrupt input. input_pool is the global BLAKE2S accumulator. base_crng
is the global root key and generation authority. crng[N] is the per-CPU ChaCha20
output generator. There is no shortcut like fast_pool[3] -> crng[3]. Entropy
collected on CPU 3 enters the global pool, and only after extraction and a
base-CRNG refresh can it influence the local generator on any CPU.
Thanks for reading this far.
Further reading
References
- [1]
Entropy sources
In random generation, an entropy source is the noisy physical process being sampled, such as timing jitter, thermal noise, or other behavior an attacker cannot realistically predict.
NIST SP 800-90B: Entropy Sources Used for Random Bit Generation - [2]
RDRAND, RDSEED, and Intel DRNG
The CPU instruction interface for Intel's hardware random generator.
Intel 64 and IA-32 Architectures Software Developer ManualsRDRANDreturns generator output;RDSEEDis aimed at seeding other generators. - [3]
DRBG
A deterministic random bit generator turns a secret seed into a long stream of pseudorandom bits. Its output is only as trustworthy as its seed and reseeding strategy.
NIST SP 800-90A Rev. 1: Deterministic Random Bit Generators - [4]
Linux RNG implementation
The kernel source for the random subsystem. It is the place where
Linux kernel: drivers/char/random.cinput_pool,base_crng, per-CPU CRNGs, extraction, and reseeding meet. - [5]
ChaCha20
A fast stream cipher. Linux uses the same primitive as a random-byte generator: a secret key goes in, pseudorandom blocks come out.
RFC 8439: ChaCha20 and Poly1305 for IETF Protocols - [6]
/dev/urandomandgetrandom()The user-facing Linux interfaces for random bytes.
random(4): Linux random and urandom manual pagegetrandom()is the safer modern API because it avoids path and file-descriptor problems. - [7]
SHA-1
A 160-bit member of the Secure Hash Standard family. It is important history here because old Linux RNG extraction used a SHA-1 based construction.
NIST FIPS 180-4: Secure Hash Standard - [8]
BLAKE2S
The 32-bit-friendly flavor of BLAKE2. In the modern Linux RNG it acts as the one-way accumulator and extractor for mixed entropy.
RFC 7693: The BLAKE2 Cryptographic Hash and MAC